 American Meteor Society
American Meteor Society

During this period the moon reaches its first quarter phase on Tuesday April 20th. On this date the moon is located 90 degrees east of the sun and sets near 03:00 local daylight saving time (LDST). As the week progresses the waxing gibbous moon will encroach into the late morning sky, limiting the opportunity to view under dark skies. The estimated total hourly meteor rates for evening observers this week is near 2 as seen from mid-northern latitudes (45N) and 3 as seen from tropical southern locations (25S). For morning observers, the estimated total hourly rates should be near 7 as seen from mid-northern latitudes (45N) and 11 as seen from tropical southern locations (25S). The actual rates will also depend on factors such as personal light and motion perception, local weather conditions, alertness, and experience in watching meteor activity. Evening rates are reduced during this period due to moonlight. Note that the hourly rates listed below are estimates as viewed from dark sky sites away from urban light sources. Observers viewing from urban areas will see less activity as only the brighter meteors will be visible from such locations.
The radiant (the area of the sky where meteors appear to shoot from) positions and rates listed below are exact for Saturday night/Sunday morning April 17/18. These positions do not change greatly day to day so the listed coordinates may be used during this entire period. Most star atlases (available at science stores and planetariums) will provide maps with grid lines of the celestial coordinates so that you may find out exactly where these positions are located in the sky. A planisphere or computer planetarium program is also useful in showing the sky at any time of night on any date of the year. Activity from each radiant is best seen when it is positioned highest in the sky, either due north or south along the meridian, depending on your latitude. It must be remembered that meteor activity is rarely seen at the radiant position. Rather they shoot outwards from the radiant, so it is best to center your field of view so that the radiant lies at the edge and not the center. Viewing there will allow you to easily trace the path of each meteor back to the radiant (if it is a shower member) or in another direction if it is sporadic. Meteor activity is not seen from radiants that are located far below the horizon. The positions below are listed in a west to east manner in order of right ascension (celestial longitude). The positions listed first are located further west therefore are accessible earlier in the night while those listed further down the list rise later in the night.
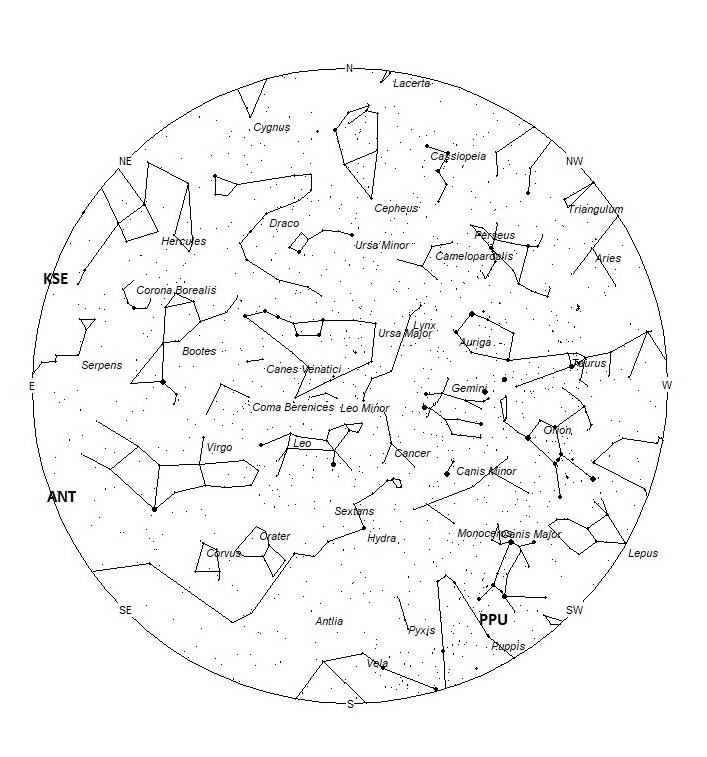
Radiant Positions at 21:00 Local Daylight Saving Time
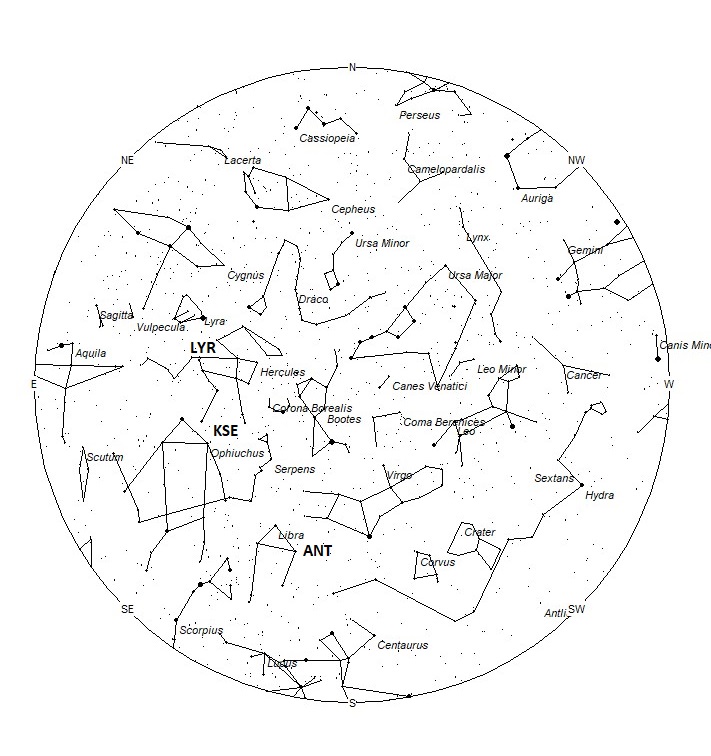
Radiant Positions at 01:00 Local Daylight Saving Time
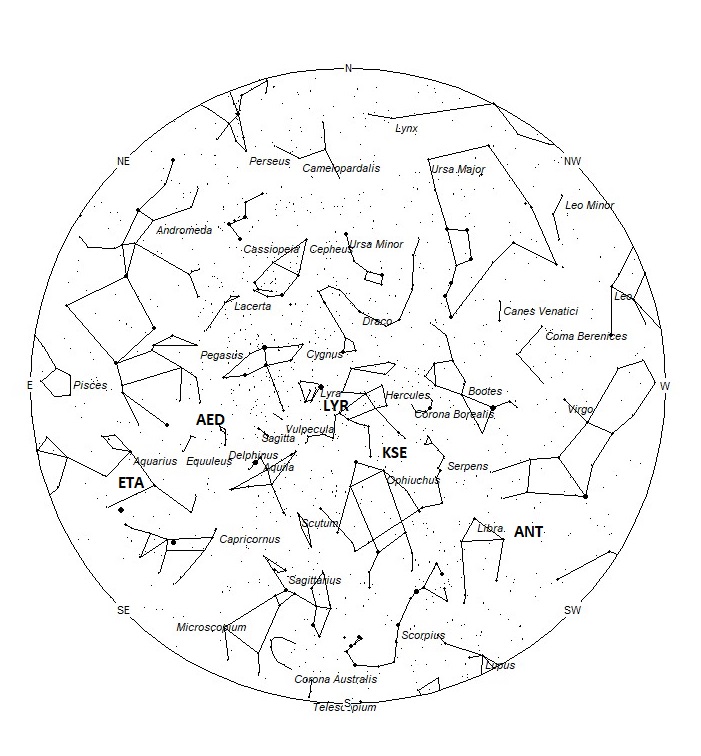
Radiant Positions at 05:00 Local Daylight Saving Time
These sources of meteoric activity are expected to be active this week.
.
The pi Puppids (PPU) are active from April 16-30 with maximum activity predicted to occur on the 23rd. Some of these meteors may be seen from the southern hemisphere from a radiant located at 07:11 (108) -44. This area of the sky is located west-central Puppis, 4 degrees northwest of the 3rd magnitude star known as Ahadi (pi Puppis). This area of the sky is best seen as soon as it becomes dark during the early evening hours. No matter your location, rates are expected to be low. Observers located in the tropical northern hemisphere may also see some activity but at latitudes north of 30 degrees north, the odds are against seeing any activity at all. At 15km/sec. the Pi Puppids would produce meteors of very slow velocity.
The center of the large Anthelion (ANT) radiant is currently located at 14:40 (220) -15. This position lies in western Libra, 3 degrees west of the 3rd magnitude star known as Zubenelgenubi (alpha Librae). Due to the large size of this radiant, Anthelion activity may also appear from eastern Virgo as well as Libra. This radiant is best placed near 0100 LST, when it lies on the meridian and is located highest in the sky. Rates at this time should be near 2 per hour as seen from the Northern Hemisphere and 3 per hour as seen from south of the equator. With an entry velocity of 30 km/sec., the average Anthelion meteor would be of slow velocity.
The kappa Serpentids (KSE) were first publicized by A.F. Cook from data provided by B. A. Lindblad, R.E. McCrosky, and A. Posen. These meteors are active from April 11-22, with maximum activity occurring on April 16. The current location of the radiant lies at 16:36 (249) +18. This position actually lies in southern Hercules, 4 degrees southeast of the 3rd magnitude star known as Kornephoros (beta Herculis). These meteors are best seen near 0300 LST, when the radiant lies on the meridian and highest in the sky. Rates are expected to be less than 1 per hour. With an entry velocity of 45km/sec., the average meteor from this source would be of medium-fast velocity.
The Lyrid (LYR) shower reaches maximum activity on the morning of April 22nd with the radiant is located at 18:10 (272) +33. This area of the sky is actually located in eastern Hercules, 8 degrees southwest of the brilliant zero magnitude star known as Vega (alpha Lyrae). This radiant is best placed during the last hour before dawn when it lies highest above the horizon in a dark sky. Rates at maximum are normally 10-15 per hour as seen from mid-northern latitudes. As seen from the southern hemisphere they will only produce 1-2 per hour as the Lyrid radiant lies much lower in the sky. With an entry velocity of 47 km/sec., the average meteor from this source would be of medium-fast velocity.
The April epsilon Delphinids (AED) were discovered by P. Jenniskens and R. Rudawska from CAMS and SonotaCo meteoroid orbit surveys published in 2014.This weak source is active from April 4-20, with maximum activity occurring on the 9th. The radiant currently lies at 20:59 (315) +17. This position lies in eastern Delphius, 3 degrees east of the 4th magnitude star known as gamma Delphini. With an entry velocity of 60km/sec., the average meteor from this source would be of fast velocity. These meteors are best seen during the last dark hour prior to morning twilight. Current hourly rates would be less than 1.
Meteors from the eta Aquariids (ETA) should begin to appear this week. Rates will be low but will slowly climb as we approach the May 5th peak. The radiant is currently located at 21:44 (326) -07. This area of the sky is located in western Aquarius, 3 degrees southeast of the 3rd magnitude star known as Sadalsuud (beta Aquarii). These meteors are not visible prior to 0200 LST and are best seen during the hour before the start of dawn. With an entry velocity of 64 km/sec., the average meteor from this source would be of swift velocity.
As seen from the mid-Northern Hemisphere (45N) one would expect to see approximately 5 sporadic meteors per hour during the last hour before dawn as seen from rural observing sites. Evening rates would be near 1 per hour. As seen from the tropical southern latitudes (25S), morning rates would be near 8 per hour as seen from rural observing sites and 2 per hour during the evening hours. Locations between these two extremes would see activity between the listed figures. Evening rates are lower during this period due to moonlight.
| SHOWER | DATE OF MAXIMUM ACTIVITY | CELESTIAL POSITION | ENTRY VELOCITY | CULMINATION | HOURLY RATE | CLASS |
| RA (RA in Deg.) DEC | Km/Sec | Local Daylight Saving Time | North-South | |||
| pi Puppids (PPU) | Apr 23 | 07:11 (108) -44 | 15 | 18:00 | <1 – <1 | III |
| Anthelion (ANT) | – | 14:40 (220) -15 | 30 | 02:00 | 2 – 3 | II |
| kappa Serpentids (KSE) | Apr 16 | 16:36 (249) +18 | 45 | 04:00 | <1 – <1 | IV |
| Lyrids (LYR) | Apr 22 | 18:10 (272) +33 | 47 | 06:00 | <1 – <1 | I |
| April epsilon Delphinids (AED) | Apr 09 | 20:59 (315) +17 | 60 | 08:00 | <1 – <1 | IV |
| eta Aquariids (ETA) | May 05 | 21:44 (326) -07 | 64 | 09:00 | <1 – <1 | IV |
Thank you so much for publishing this data!! I absolutely LOVE watching the showers! My brother who was 10 yrs my senior started taking me out into the country when I was 4 or 5 yrs old to watch the showers. He always had such interesting things to show and teach me. I don’t think we missed a visible shower for 3 decades!! I haven’t been able to watch one since his passing but it came to me that he absolutely would not want me to be like this!! So here I am . Thank you again for the time you spent gathering this much valuable and informative information!! Loved reading it! Stay safe and watch out for falling objects! LOL